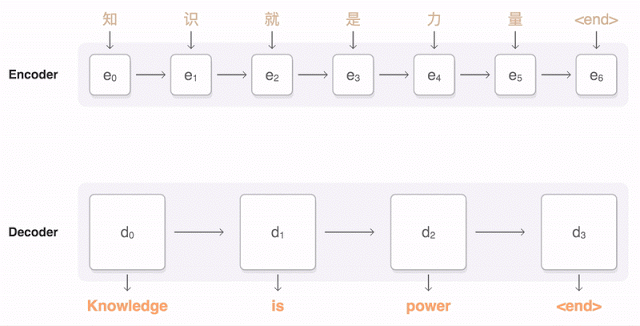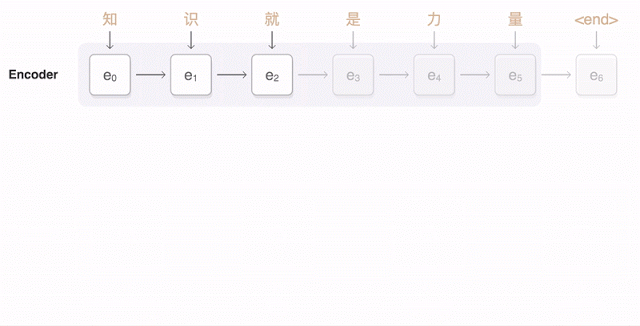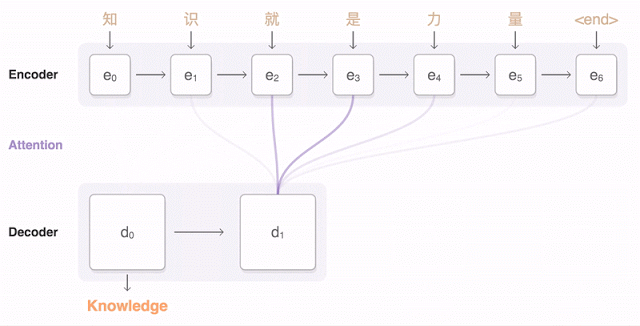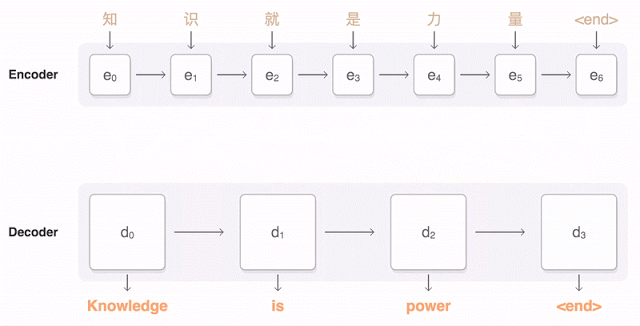
谷歌神经网络翻译将例句中的中文单词编码为一系列向量,每个向量代表整句话所有单词的含义。
日前,谷歌推出神经网络翻译,翻译质量接近人工笔译。这让人们不禁发出感叹:“是不是以后我们都不用学英语了?”
早报记者 徐明徽 实习生 李娇
9月27日,谷歌推出了新的翻译系统,声称该套翻译系统基于对于人类神经思考的模仿,能够与真人翻译竞相匹敌。
继阿尔法狗战胜韩国职业棋手李世石没多久,人工智能再下一城。9月27日,谷歌推出了新的翻译系统,声称该套翻译系统基于对于人类神经思考的模仿,能够与真人翻译竞相匹敌。
在谷歌的发文《规模生产中的神经网络机器翻译》(A Neural Network for Machine Translation,at Production Scale)中,宣布将机器学习技术纳入网页和手机APP翻译中,从前汉译英的尴尬局面将大为扭转。
翻译系统面世后,根据用户们的测试,发现汉译英的准确率高得惊人。
众所周知,将汉语恰切地译介为英语是一件不易之事。输入中文,翻译系统给出的答案往往是“惨不忍睹”,简单的机械翻译对于那些谷歌翻译的依赖者来说已远远不够。谷歌公司称,相较之前的算法,谷歌神经机器翻译能减少80%的错误,与通过标准测试的真人翻译所差无几。
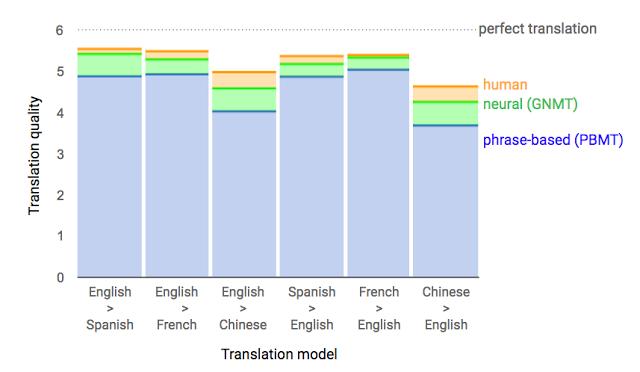
在之前的一项西班牙语译为英语的测试中,设定满分为6分,谷歌旧的翻译系统得到3.6分,人类普遍得分为5.1分,而谷歌的新系统得到了5分的好成绩。
三种译介方式评估。分为6分,橘色为真人翻译,绿色为谷歌神经网络翻译,蓝色为短语式翻译。
谷歌神经网络翻译为何能够在准确性上有质的飞跃?
据悉,谷歌神经翻译克服了之前神经机器翻译在准确性和速度上的缺陷,带有8个编码层和8个解码层的长短时记忆(LSTM)网络用来增强注意以及记录瞬间感觉残留。注意力机制则连接下层解码层和上层编码层,以此来提高并行度从而降低耗时,推理计算中的低精度的算法则提升了最终的翻译速度。
谷歌神经网络翻译汉译英進程图
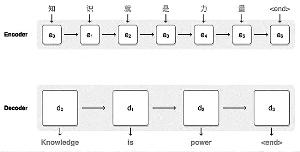
第一步,网络将中文单词编码为一系列向量,每个向量代表整句话所有单词的含义。一旦整个句子被神经网络阅览,解码即开始,生成相应的英语句子。而解码则是一个将已编码的中文向量与相关的英语单词生成的加权分布的过程。连接编码解码的曲线代表解码过程中所考量到的编码词汇。
而为提高对生僻词的处理,谷歌将词语分成有限的子词单元,从而方便输入与输出。而束搜索技术则使搜索长度规格化以及具有覆盖性,这使得翻译输出的句型可大量覆盖译介语种的所有单词。这一切都可归为人工智能,人工智能算法不依赖于人类逻辑,比起人们从前使用的手工编写的算法来说,人工智能算法能找到更好的方式完成任务。人工智能网络自身会学习怎样翻译,它专注于结果如何,而不受人类思维优先的干扰。麦克·舒斯特,开发此项目的谷歌工程师说,“你不必选择,系统会全面進行翻译。”
中译英只是谷歌翻译所支持的一万种语言中的一种。谷歌表示,今后翻译将更多依赖于人工智能。在之后的几个月时间里,谷歌还会设计出适用于更多语言的谷歌神经机器翻译。当然,此种神经机器翻译还不能称得上完美,固然基于神经的人工智能表现不错,但仍有很多细微之处机器算法不能够真正领悟。比起人类翻译,谷歌神经网络翻译仍会犯许多人类翻译不会出现的错误,如掉词、误译专有名词、罕见术语,以及忽略上下文语境孤立翻译某句话等等。不过,起码这种新的翻译模式只是让意思流失在翻译结果上,而非在翻译过程中就面目全非。
許多外國人一致認同中文是最難學的語言,不僅有著 4 種語調,每個字與每個字在不同的組合下又有著不同的涵義,實在是令他們相當頭痛,這時,有人就會藉由 Google 翻譯來一解中文的奧祕,但有時有不免被翻譯的句子逗得好氣又好笑。為了解決這個問題,Google 翻譯近期採納了新的翻譯系統,讓中翻英不再怪裡怪氣,能更貼近人類所說的句子。
Google 翻譯已成為現代人愛用的翻譯工具之一,但 Google 不想將其翻譯工具的功能只侷限於「字典」,要讓它能夠更進一步的完整表達中文句子。27 日,Google 在其官方部落格上宣布,Google 翻譯採納了新的深度學習系統,用了此新翻譯系統能讓中翻英的表達更加完整且符合原文文意,並將其同步推送至 Google 翻譯的 App,讓需要的人使用。
Google 將新的翻譯系統稱為「Google 神經機器翻譯(GNMT)」,不同以往將每個句子中的單字與語詞拆開來去理解與翻譯,GNMT 能夠在考量整句中文的涵義以後,再翻譯成較通順的英文句子,更能貼近原文含意。
▲ Google 翻譯採用 GNMT 的新翻譯系統所翻譯出的英文句子比較。(Source:Engadget )
根據 Google 的說法,GNMT 所翻譯出來的句子較原先的 PBMT 翻譯系統通順,雖然它一樣會將句子拆散成獨立的個體看待,但不一樣的是,它會自動考量句子前後的文字關係,最後再進行翻譯。但目前這項功能僅限於中翻英而已,Google 表示他們也會盡快將此新翻譯系統擴展到其他的語言上,供用戶使用。
對於母語是英文的人來說,若要嚴格看待 Google 的新翻譯系統所翻出來的英文句,其句子僅能是勉強及格,但比起先前讓人好氣又好笑的翻譯已有非常大的進步。Google 也坦承,要能真正翻出中文所要表達的含意,並且又要能讓語句通順是相當困難的事,要能真正接近那樣的程度,Google 翻譯還有很長的一段路要走。
相關連結
近日,Google宣布发布Google神经网络机器翻译(GNMT:Google Neural Machine Translation)系统,该系统使用了当前最先进的训练技术,能够实现到目前为止机器翻译质量的最大提升。
十年前,Google发布了 Google Translate,这项服务背后的核心算法是基于短语的机器翻译。自那时起,机器智能的快速发展已经给语音识别和图像识别能力带来了巨大的提升,但改进机器翻译仍然是一个极具挑战的目标。
几年之前,Google开始使用循环神经网络来直接学习一个输入序列(如一种语言的一个句子)到一个输出序列(另一种语言的同一个句子)的映射。其中基于短语的机器学习将输入句子分解成词和短语,然后对它们的大部分进行独立翻译,而神经网络机器翻译则将整个输入句子视作翻译的基本单元。这种方法的优点是:相比之前的基于短语的翻译系统,这种方法所需的调整更少。在被首次提出时,神经网络机器翻译系统在中等规模的公共基准数据集上就达到了与基于短语的翻译系统不相上下的准确度。
自那以后,研究者提出了很多改进神经网络机器翻译系统的技术,其中包括模拟外部对准模型来处理罕见词 ,使用“注意(attention)”来对准输入词和输出词以及将词分解成更小的单元以应对罕见词。尽管有这些进步,但神经网络机器翻译系统的速度和准确度仍有很大的提升空间。而现在通过让神经网络机器翻译系统战胜在非常大型的数据集上工作的许多挑战,Google打造了一个在速度和准确度上都已足够为用户带来更好服务的翻译系统。
下面的可视化图展示了Google神经网络机器翻译系统将一个中文句子翻译成英语句子的过程。首先,该网络将这句中文句子的词编码成一个向量列表,其中每个向量都表示了到目前为止所有被读取到的词的含义(编码器“Encoder”)。一旦读取完整个句子,解码器就开始工作——一次生成英语句子的一个词(解码器“Decoder”)。为了在每一步都生成翻译正确的词,解码器重点注意了与生成英语词最相关编码的中文向量的权重分布(注意“Attention”;蓝色连线的透明度表示解码器对一个被编码的词的注意程度)。
使用人类对比评分指标,神经网络机器翻译系统得出的翻译内容相较于之前实现了极大的提升。在双语评估者的帮助下,通过在维基百科和新闻网站的例句测定,Google发现:在多个样本的翻译中,神经网络机器翻译系统将误差降低了 55%-85%甚至以上。
同时,Google还宣布将神经网络机器翻译系统投入到了一个非常困难的语言对(中文-英语)的翻译中。现在,移动版和网页版的 Google Translate 的中英翻译已经开始完全使用神经网络机器翻译系统了——每天大约 1800 万条翻译。其中,Google开放的机器学习工具套件 TensorFlow 和张量处理单元为部署强大的神经网络机器翻译系统模型提供了足够的计算力,同时也满足了 Google Translate 严格的延迟要求。中文到英语的翻译只是 Google Translate 所支持的超过 10000 种语言对中的一种,在未来几个月,Google还将继续把神经网络机器翻译系统扩展到更多的语言对上。
但机器翻译的问题并没有完全解决。Google神经网络机器翻译系统仍然会犯一些人类译者永远不会出的重大错误,例如漏词和错误翻译专有名词或罕见术语,以及将句子单独进行翻译而不考虑其段落或上下文。为了给用户带来更好的服务,Google还有更多的工作要做。但Google神经网络机器翻译系统仍然代表着一个重大的里程碑,Google希望与过去几年在这个研究方向上有所贡献的研究者和工程师们一起庆祝它的诞生。