今天我给大家分享的一个题目,叫做深层世界中智能的大语言模型,这里面有很多的一些术语,就是希望我今天主要是起到一个普及性的作用,让大家去了解一下这些东西,现在特别热门的这些什么chatGPT,GPT,然后还有什么 BERT LLaMA 这些东西它到底是什么?以及你在网上看到那些自媒体发的那些视频,那些东西有多少是真的,有多少人是假的?就我们既不要那个妖魔化这个东西,也不要神化这个东西,它能做到什么?它不能做到什么。这里面其实就有两个比较重要的概念,一个叫生成式的人工智能,一个叫做大语言模型。
首先我们来看一小段视频,这是今年 Nvidia 公司做的一个 AI 的一个宣传视频,当然这个视频里面有一些大家可能看不是很明白他在干什么,但是最后这个我想应该看明白,就是这个宣传片整个的脚本都是这个人工智能写的,然后他配的这个背景音乐是人工智能编的,就是他他会创作音乐,然后那里面提到很多现在 a i 这个比较前沿的一些东西,就现在的 AI主要从事的是很多创造性的工作,这是跟以前AI 一个非常大的不同。
那么这里面有几个我觉得大家需要去知道一下的几个比较关键的概念。第一个叫AGI,就是人工通用智能,它跟AI 不一样,人工通用智能指的是我们在人工智能发展领域上,可能说是最后一部分,就实现一个像科幻电影里面的那种人工智能。如果大家看过那个钢铁侠的话,里面钢铁侠的一个助手贾维斯,这就是一个科幻里面所谓的通用人工智能的一个代表,那么这个是人工智能发展的一个方向,或者说一个理想。
当然现在我们没有达到它,我们离它有多远其实没有人知道,包括现在非常厉害的ChatGPT,它离人工智能之间的距离也非常非常远,甚至可以说我们并不知道 ChatGPT 最终能不能实现人工智能,它甚至有可能这条路走下去,我们会发现这条路是走不通的,因为在人工智能发展历史上已经出现过很多次这种事情,就是在当时非常新的技术大家都觉得前景特别好的技术,然后最后走下去之后发现走到一个死胡同。
第二个叫做大语言模型LLM,它是ChatGPT,包括现在谷歌的BERT这些新的模型技术的一个分类,他们主要就是通过学习大量的人类的自然语言数据来让他掌握其他方面的知识,而不仅仅是语言方面的知识。而 GPT 就是 OpenAI 这个公司出的一个模型,叫做 generative pretrained transformer,这个东西里面有很多专业的词,大家不用去搞明白它到底是什么,你只要知道它是 OpenAI 这个公司开发的,所以其他公司出的类似的东西,理论上它不能叫做什么什么GPT。

那么在人工智能的发展历史上,我们稍微了解一点,人工智能不是一个新东西,它非常非常老,它可以追溯到计算机刚出现的时候, 1950 年人工智能就开始出现了。图灵写的计算机与智能,而是被称为人工智能的开山之作,所以图灵也被称为人工智能之父。在那个年代计算机其实并没有出现,所以人工智能和计算机本来是两个领域的东西,只不过计算机这个领域它刚好特别适合人工智能发展。 1960 年最早机器人程序出现, 1970 年的,这可能会超出大家想象,我没查资料的时候,我也没有想到,就 1970 年就已经有机器人问诊了。
1979 年斯坦福大学已经开始研究自动驾驶的基础,就是人类的技术发展,其实跟我们大家想象的并不一样,就我们现在觉得很新的很多技术,它的历史会久到你没有办法想象,比如说电动车,电动车的出现比汽油车要早,但是他在一开始出现的时候他并没有那么好的发展,因为技术发展的路线他要经过很多的不同的选择。
1974 年到 1993 年这段时间里面, AI 处于一个低谷,就是有我们现在如果严格说的话算是第三次的 AI 浪潮,然后在那之前有过,两次就是 AI 的泡沫的破灭,这些技术都被实践证明是走不通的。虽然在当时如果只看当时的新闻的话,大家会觉得我们离人工智能已经很近,就跟现在的宣传的这个调子是一样的。我还记得我大概十几岁那时候,当时那个深蓝战胜了人类的卡斯帕罗夫,人类的那个国际象棋冠军,当时宣传的全世界都是,但是后来就是很快就证明深蓝的那条技术路线是死不通走不通的,然后就遭遇了一次寒冬。然后 1990 年代主要的运动技能智能是基于机器学习的一些聊天机器人,基于规则判断的一些聊天机器人。然后最近的这次从深度学习,从神经网络开始,从李飞飞领导的那个 image net 开始,引起了一波图像识别的最先发感器。然后接下来是alpha go又带来一点新的热潮。
在围棋上战胜了人类,这在当时被认为是一个不可能完成的任务,因为围棋相比于国际象棋来说,它的可能性是好几个数量级的,区别就是人类是没有办法穷尽围棋棋盘上所有可能性。所以当时觉得我们在计算机领域想让机器战胜人,在围棋上机器战胜人类,当时还是看不到希望,但是突然一下阿尔法狗突然出来,就把人工智能又推出一个新的高度。
其实前两年就是在我们疫情刚开始的时候,这个人工智能已经开始慢慢开始走下坡路了,像语音识别也好,图像识别也好,基本上走到一个尽头的,就我们的人脸识别、图像识别这些东西都已经走到大家觉得已经无路可走的程度了,然后突然一下子 ChatGPT 出来,大概是去年前 12 月份的时候, ChatGPT 出来一下子又把这个整个推到一个非常高的一个高峰上面去。这是人工智能大概的一个发展路线。
那么接下来我们今天主要就是来讨讲一下什么叫大语言模型,大语言模型到底有多大?以及为什么这次新的突破?它是从大语言模型经常出现的,而不是我们最早开始人工智能这一次发展最早是从图像识别上开始,识别猫狗,识别手写数字,然后到识别人脸,识别各种物体。但是为什么我们现在觉得通用人工智能 AGI 可能会是由大语言模型也就出现,这是大语言模型的一些介绍。
大语言模型主要指的就是对机器通过对于人类的自然语言 natural language的处理来学习语言背后的这些逻辑知识,而不是语言文字本身。然后通过这样的学习之后,它能够生成语言输出。那么大语言模型里面一个特别重要的就是一个大,这个大语言模型到底有多大?所以拿 GPT 来说, GPT 其实出现了好几代,GPT 3 它有 45 个 t b 的训练数据,那么整个维基百科里面的数据只相当于他训练数据的 0. 6%。我们在这个训练的时候把这个东西称作语料,就语言材料,这个语料的量是可以说是集中到我们人类所有语言文明的精华在里面,这是一个非常非常庞大的一个数据库。嗯,经过这样的一个量的学习之后,它产生的一些就是做 AI 的这些计算机学家们,他们没有想到的这种变化。
这是一个语言模型的一个发展,这边是它的训练量,也就是它的语料的量。还有一个重要的东西叫做参数,它跟语言的量不一样,但基本上你们可以把它理解成这个模型本身的神经数量。
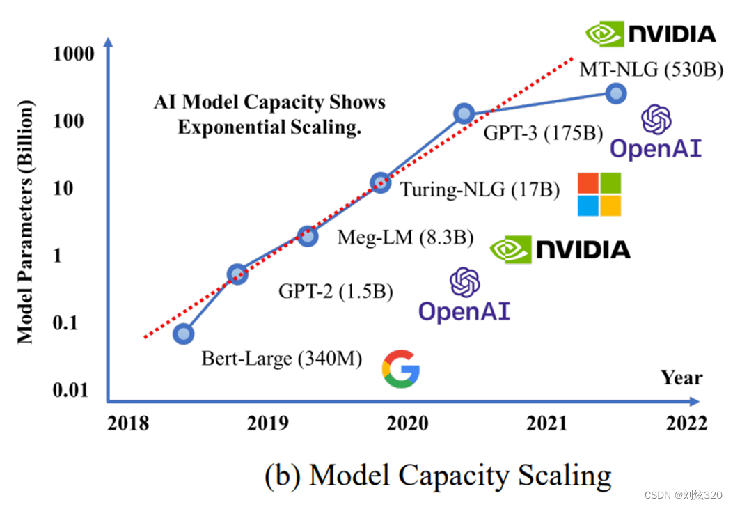
回顾一下语言模型的历史, 2018 年的时候谷歌提出了 Bert 的模型,然后到 GPT 2,从 340 兆到 10 亿 15 亿,然后到 83 亿,然后到 170 亿,然后到 GPT3 1750 亿的参数。这是大语言发展的历史,最早的是一 2017 年出来的,就是我们刚看到这个那个GPT, GPT 名字里面有一个叫做transformer,就是这个 transformer 这个模型。它是 2017 年出现的,其实也很早,所以计算机领域来说, 2017 年可以归结于上一个时代的产品。然后 2018 年第一代 GPT 出来,当时还不行,相对来说比较差,性能也不行,然后像一个玩具一样。然后 2018 年谷歌又推出了一个新的模型,叫BERT,但是这些模型都是基于这个之前谷歌推出的这个 transformer 这个模型,它进行发展。然后到了 2019 年, open AI 除了 GPT 2 也没有什么特别,就是它没有办法来产生一个语言逻辑流畅通顺的一段名词,你一看就知道这是机器写的。
但是到了 2020 年的5月, GPT 3 出来之后,其实就有了非常大的变化, GPT 3 的性能比 GPT 2 好很多,它的数参数的数量级大概是 GPT 2- 10 倍以上。但是 2020 年5月的时候,其实大家就整个世界上对于这个东西没有什么反应,一直到 2022 年 12 月份 ChatGPT 的出现之后,一下子把这个整个引爆。但 ChatGPT 使用的还是基于 GPT 3 的一个模型,就它本质上跟 GPT 3 它并没有一个特别大的技术的差距,因为 ChatGPT 它使用了一个非常新的手段,就是它用对话的形式来让你去体验它。
那么刚刚降到一个大语言模型,它最终它只是一个背后的一个模型,一个算法,它最终我们用到的是什么呢?是 ChatGPT 这种界面,它是一个给大家看一眼 ChatGPT 的界面,它是这样一个,就是它是一个聊天窗口,你在下面打字,他给你回应,你给他打不同内容,他会给你不同的回应。
这里有一些对话,我给了他一个数学的一个描述,我让他帮我写一段,我给它一段数学这个函数的描述,然后它帮我去生成一段代码,然后它会有一些相应的解释,然后这里是我给了他一段数学公式,然后他来解释这个数学公式到底是什么意思?然后他也可以做一些其他的事情。这里是一段,我让他帮我写一段文字,我要申请一个 ChatGPT 的一个功能,我让他帮我写一封申请信。
这里是一段翻译,这里是一个翻译,给它一段英文,让它翻译成中文,你也可以反过来,这个就是我们所谓的生成式的 a i,他的内容是他自己现场自己产生的,他并不是从网上去找到任何一个内容给到你,他也不是从字典或者数据库里面查到一段内容给他的学习过程。
这个语言模型的学习过程其实跟我们人类的学习非常像,我们人类在读书的时候,你不可能把一本书都背下来,我们读书的目的也不是把那本书背下来,我们学习的时候我们做过的题目也不可能全都记得住。
但是你在学的过程当中你学到的是什么?你读书的时候,你读完了之后你读到的是什么?那么我们在对于 AI 来说,就是他把那些海量的文字给到他之后,他掌握的是这个文字背后的一个逻辑关系,他并不理解文字的意义,或者说他没有人类意义上的这个理解的能力,但是他会掌握什么呢?他会掌握一个叫做概率,我知道这个词后面可能会接一个什么词,但是为什么会见这个词?他不知道。

接下来我们看一张图片,这是一个所谓的生成式AI,一个非常有意思的一张图片,这张图片首先它不是照片,然后他也不是 PS 出来,这是那个星球大战里面的一个角色。然后这一章就你给他一段文字描述,然后 AI 会自动给你生成出这样一张照片。你在描述里面你可以告诉他,我要的场景是什么?我要的这个背景是什么?我需要有多少个人?我需要人的形象是什么?然后我需要这张图片的风格是什么?是一张照片还是一张素描,还是一张油画?如果是照片的话,我需要这张照片的摄影师的风格是什么样子,我甚至可以指定这张照片使用的是什么相机,它的一些摄影参数是什么?然后它会根据你要求去生成,而且它生成非常快,几秒钟就能生成出很多张照片,然后你可以从里面去挑选,你需要,那当然不是每一张都有这样的质量,可能在 10 张、 20 张里面挑出一张,这种效果比较好。
所谓生成式 AI 就是它产生的内容是创造出来的,不管是文字、声音还是这种图像,都是它创造出来。就这张照片在这个世界上是不存在的,它里面的每一个元素在世界上都不存在。它并不是把一些已有的照片拿过来拼起来, a i 产生的文字也是这样,就是你让他回答一段话,他并不是去找到几句跟你想要的东西差不多,把它拼接起来,它是完全现场生成出来的,但是因为有训练语料的关系,所以它生成的东西你看起来会觉得很有道理,很通顺,甚至会有一点眼熟。
这个跟我们人类学习也是非常相似的,语文老师的话可能会比较清楚,就学生这段时间他一直在看某一类的书,他写的东西就会有一点点那种风格, AI 也是这样的,就他写出来的这个东西取决于你给他什么东西去训练。这是 a i 生成的一个照片,一张人脸,旁边这段文字就是我们写给AI的要求,就是 a i 怎么知道你要生成什么,你就把这段文字给他,当然它不会每次都生成一样的,它每一次生成的都不一样,但是它会抓住你给它的这句话里面的重点。这个文字在生成式的AI,无论是我们说的ChatGPT, PR 还是纹身图的那种模型里面都非常重要,这个叫做Prompt,就是现在已经有专门一个研究就怎么样把这个话描述到准确,描述的有创意,这已经成为专门一个领域了,也在网上找到非常多相关的内容。甚至在国外很多公司里面有专门的这个职位,叫做 Prompt engineer,就你不用去懂怎么去使用 Photoshop 这种东西,你也不用懂 AI 背后那些数学和算法,你也不用懂代码,你只要知道我怎么样把这句话写给 a i,让他照着这段话去做。你相当于一个翻译,你把你的需求翻译成 AI 能够执行的一个命令。这里有很多的细节,就你我们怎么样把我的需求表述清楚,这其实是一个蛮重要的一个能力,因为对于很多人来说,其实他并不知道自己需要什么。
很多人在解决问题的时候我有问题,但是我并不知道这个问题怎么去把它描述出来。可我需要解决的东西是什么,我是说不明白的。然后如果当你使用ChatGPT,你就会发现,如果你没有办法准确地描述你的问题,那么 AI 它就没有办法去帮助理解。而这个能力我觉得可能是我们目前学生也比较缺乏,他们没有办法把自己的这个东西,脑子里这个东西准确地把它说出来。
那么语言模型本质是什么?它是一个文字接龙,就是他学了大量的文字之后,他会有一个感觉,就可能英文老师会比较提的比较多的语感,什么语感?他也有语感?对,他会觉得这个 the best thing about AI is stability to,后面他觉得应该接这些单词,然后每个单词它会计算出一个概率,我有百分之三 4. 5 的把握,它后面应该接learn,我有 2. 9% 的把握后面接应该接do。

第一,它这个计算每一次的时候这个概率都会有变化,不是死的。第二,它并不是机械地说我一定to,后面会把概率最大的一个词放进去,它会加一个稍微有点变化的随机数,这样的话它的生成的内容就会发生变化,它每次不一样,否则的话它永远产生的就只有这一句话。
所以本质上,诶,这个语言模型它就是一个文本接龙,它并不理解这句话是什么意思,它只是知道,就我根据你们人类说话的习惯,我觉得这句话应该这么说,你会觉得它很通。所以,这就是为什么你在网上看到早期的那个ChatGPT,它会给一些非常好笑的回复,但是它的语言是非常通顺的。
在早期会有人问他,比如说你问他林冲和林黛玉什么关系,他就会帮你编一个,他们两个是兄妹关系,什么能编一整个故事出来,就是它并不是去它的数据库里面去搜林冲是谁,林黛玉是谁?它是根据人类的习惯现编一篇小作文出来。
这里有个非常好玩的一个,就是我之前问他,让他推荐一些书给我,然后他推荐了 5 本名字听起来非常厉害的书,然后有出版社,有作家,我搜了一下是真实存在的。好,就是领域的大牛出版社也是国际的顶级出版社,但是这本书是不存在的,哈哈哈。然后如果你要问他这些,你问他一个观点,然后他给你回答,你问他,你能给我一个出处吗?他会给你一篇论文,而这篇论文也是不存在的,叫论文名字是编的,但是编得非常像真的多。然后论文的作者有的时候是编的,有的时候是真实存在的。作者就是取决于他学习的语料里面他有没有学到这一块。如果他有学到这个人名字,再把这个人名字拿出来。但是这篇论文本身是编的,所以 ChatGPT 它可以帮助我们解决一些问题,但是你不能把当一个搜索引擎或者一个知识库的知识系统来使用。然后我问他能做到什么?这么多事,他可以回答一些一般性一些基本事实的问题,他可以提供一些建议和想法,它能够帮你写一些东西。
我试下来写邮件,特别好,尤其是给老外给邮件,他英文肯定比我好,然后包括它的翻译,等会我们回到这里来看刚刚这段翻译,这段翻译这全是它是一个什么?就这段翻译我们从语言的这个规范性,或者说从这个官方程度上来说,肯定比我写得好,我写不出这么官方的用词来,所以他可以去做一些我觉得是一些套路化比较强的一些事情,它也可以做一些像帮你提供一些 idea 的事情。
我刚刚给大家看的那个里面的,它可以解释一些数学的公式,它可以帮助你编写程序,这个是它的强项,它的代码写得非常好。但是第一,它不能提供实时的信息,它的数据库截止到 2021 年的9月,就 2021 年9月之后发生的事情他都不知道,就算他回答对了,他也是变的,就让他碰到。然后第二,他不能访问网页,你给他一个链接,他会很认真地告诉你这个链接里面讲的是什么,但是他是没有能力访问这个链接,所以他所有的回答全是编造的。但是有的时候他们编得非常像,因为我们给他的链接里面会有一些关键词,就链接里面会有比如说这篇文章的标题的一些关键词,在这个链接里,它会根据这个关键词现编一个关于这个链接的一个总结给你。然后他不保证准确性。什么叫不保证准确性?就是他不会对自己产生的答案再做一个事实性的检查,你要自己去做事实性检查,尤其是专业领域上的东西,他给你的答案有可能是听起来靠谱,但实际上是不对的。包括我让他做数学题,也是就他会写很长一段的那个方程的求解的过程,然后最后答案是错的,就每一步写的特别自信,特别认真,一本正经胡说八道。
所以我们在使用这个东西的时候,你必须要先有一个预设,就是我要用它来做什么,然后我让他做这件事情他能不能做到?然后我在这个过程当中我要做什么?如果你想的是我抛一个东西给他,然后我就不管了,他直接给我一个最终成品,那他是做不到。但是他可以,比如说我要写一篇论文,然后我现在有一个大概的想法,我没有细节,它可以帮你。比如说给你一个大纲,给你一些方向性的引导,然后或者反过来你有了一个大纲,然后里面有一些文字你可以丢给它,让它帮你去进行润色,进行修改,这些是它可以做到的。但是你指望说我丢一个论文题目给它,这篇文就交给你了,那他做不到。他在很多领域,其实都是有缺陷的,因为他在学习的过程当中,第一他学习的语料未必会覆盖这个相关的学科。第二就是他学习的他学完之后他会忘,他会忘掉很多东西,它并不是把学习那些语料都存到它的数据库里面,然后你要问到它去进行检索,它是把你给它的那些语言文字他进行了一个压缩处理,然后得到的是这些东西背后的这样一个逻辑结构,或者说刚才我们看的是一个概率,那么基于这个概率它再重新生成和计算。
就跟我们学生上课一样,有些学生就是做数学题,它前面做的方法都是对的,但最后就是答案是错的。就他在学的过程当中,他学会的一部分,他会忘掉其中的一部分,他会忘掉他觉得不重要的那部分,往往是一些具体的细节。然后他在你问题的时候,他现场根据他记得的那个框架去生成,去填充细节的内容,而这些细节的内容它是可能会填充错的,因为它是一个覆盖各个学科的一个通用的语言框架,它不是针对某一个学科的专业知识库。
所以现在网上有很多人基于 ChatGPT 推出了一些更加窄一点的专用的一些工具,就是我给在它的基础上我给它一些专门的语料,然后限定它在回答的时候你只能从我提供的这些语料里面去查,比如说我把教材扔进去,然后我问的问题,我要求你只能在我给你的这些教材里面去找,那么这样的话它的答案会更加的准确。
所以大家在使用的时候要自己去做事实核查,凡是涉及到事实的地方,你都要再去做核查。因为他在网上学习的时候,他学的那些材料有可能本身是错的,然后他学的过程当中他还会忘,所以你一定要自己去做事实的。第二,它不是一个搜索引擎,不要让用它去搜一些事实性的东西。它是一个更加偏向于创意的工具,它是一个创造性的东西,他的记忆力并不好,你跟他对话的时候,你对话稍微长一点,他会忘记你前面问过他什么。我让他写代码,简单的代码他一口气能写对,然后如果只要改一次两次,他也能改。对,但如果这个代码比较复杂,我让他改到第五轮,第六轮他就忘了他前面写过什么,他就开始给我乱编,那我又要把他写过的代码重新发给他。你刚刚写的是这个,请你基于这个才进行修改,否则他就会前言不搭后语。
一个特别有意思的是,他不会做计算,尤其是就是小学的计算,他会经常在计算上出错,但是他能够把高等数学的那些微积分量的公式解释得非常清楚,所以就他在训练的时候,我们给他只是一些语言材料,他没有接收过数学的训练,他也不具备运算功能。他对数学的所有理解都是基于语言而产生的。所以这就是为什么现在说这个大语言模型能够导向通用人工智能。就这个原因就是计算机学家或者说搞 a i 这一批人,他们认为我们能够从文字里面掌握人类思维的本质。
他没有学过数学的规则,他学的都是一些文本资料,但是在这些文本资料里面或多或少会包含一些数学的东西,那么他从这些东西里面他就掌握了一些数学的规律,包括他其实也能够掌握一些视觉的颜色、空间上的能力,你可以问他一些空间的方位或者颜色的,这个哪个颜色跟哪个颜色之间什么关系,它也能够给你。
但是它没有视觉能力,它训练的所有语料都是文本,它没有输入过任何一篇图像进行训练,所以这是一个特别有意思的事情。也是上个星期就是在 AI 这个领域炒了一个特别厉害的。我不知道大家有没有看过新闻,就马斯克一帮人写了一封公开信,要求停止大语言模型的训练至少 6 个月,让他们觉得这个东西对人类会造成很大的危害。那么大语言模型到底能不能够导向通过人工智能?其实是不知道,就只是说目前看来它是一个在目前我们人类已知的人工智能的技术路线里面,它是最有可能突破到通用人工智能的一条路线。
接下来我们来看一小段open AI的首席科学官在接受采访时说的话。
那他讲的什么意思?就是说在他们看来我们的语言材料,我们的语言材料是我们人类对于这个世界认识的一个压缩,所以我们能够通过学习这些语言材料来掌握我们人类对于这个世界的一个认识,基本上就是这样一个意思。
而且 GPT 从网络上重新表达材料,不是逐字引用,这让它看起来像是一个学生用自己的话来表达思想,而不是简单重复它读过的,它会造成 ChatGPT 理解的这个材料的错觉。这里面有一个我觉得非常有意思的问题,就是什么叫做理解?还是回到我刚刚的这个例子上,这里,这里,我让他去帮我解释一个数学公式,这是用那个 latex 语言写的,因为这个数学公式我没有办法用图片的形式告诉他,我就用代码的形式告诉他,然后他看懂了,然后把这个数学的公式解释得非常清楚,然后根据这个数学公式写了一个函数的代码来帮我进行这个公式的计算。那么它算是理解这个公式吗?因为这个题目他肯定没有学过,这个题目是一个很一个新的一个在线课程的作业,他肯定没有学,他算是理解了这个问题吗。然后第二个就是我用这个工具,我把这个作业做完了,我算是理解这个问题吗。
那么在这个过程当中,它产生的这个模型和我们人类学习的这个模型思维的模型到底有什么区别?所以为什么说它能够可能导向通用智能?就是大家觉得我们可能在这个方向上找到了人类思维的一点点秘密,就当你的这个参数,也就是我们可以理解成人的神经元足够大的时候,它会产生一个叫做涌现的现象,它会产生一个量变到质变的一个突破,当你的数量训练的量不够大的时候,你训练出来的模型是没有这个能力,只有它突破了那个层级之后,它就能够展现出这样的能力。
理解力、创造力、逻辑思维。而这些东西是在人工智能刚开始的时候,那些专家们,我想大家应该都还记得,报纸上电商专家们都说这是人类不可能被 AI 替代的东西,我们人类的思维的这个创造力、理解力真的像我们想的那么高级吗?
那么我们人类思维的独特性到底在什么地方?这是 OpenAI 最近的一个调查,他说大约 80% 美国劳动力工作内容当中,至少有 10% 会受到 GPT 的影响,有 19% 的劳动力可能会受到至少 50% 的影响。最有意思的是,后面,高收入的工作面临更大的风险,尤其是那些我们所传统上认为不会被 AI 取代的一些工作。会计,律师,艺术师,艺术家。后面还有一张对比图,这些是会受到影响和不会受到影响的职业。

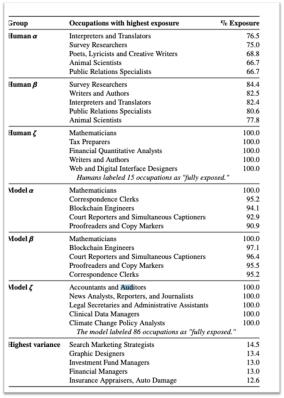
那些服务员、码头上的工人、搬运工、建筑师,就是这些我们传统意义上认为是最容易被机器取代的工作,现在是被认为是受到AI 影响最小的工作。而程序员,翻译,这些工作是受到影响最大,比如说翻译,我现在我打开一个程序,我翻译一本书大概也就两三个小时,成本大概就是 1 美金到 2 美金左右,然后他翻译出来当然肯定没有大翻译家的文字那么好,但是对我来说能看懂,而且比现在市面上绝大部分的翻译要好。
所以,我觉得这里留给我们思考的就是我们到底在这个过程当中,我们要培养学生什么样的能力。
参考资料和推荐阅读:
OpenAI最新报告——LLM(大语言模型)对美国劳动力市场潜在影响https://zhuanlan.zhihu.com/p/617194004
What Is ChatGPT Doing … and Why Does It Work? https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
黄仁勋与OpenAI首席科学家Ilya Sutskever的炉边谈话 https://www.bilibili.com/video/BV1Tc411L7UA/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=5f3dfaeb7b92a24516d74b5e0327cf80
OpenAI CEO Sam Altman 谈 GPT-4、ChatGPT 和 AI 的未来 中文字幕 https://www.bilibili.com/video/BV1cM4y1U7WV/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=5f3dfaeb7b92a24516d74b5e0327cf80
《降临》作者特德·姜:ChatGPT是网上所有文本的模糊图像https://m.thepaper.cn/newsDetail_forward_21877769
Chat GPT是怎样练成的!https://www.bilibili.com/video/BV1JR4y1C7Vt/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=5f3dfaeb7b92a24516d74b5e0327cf80
GPT,GPT-2,GPT-3 论文精读https://www.bilibili.com/video/BV1AF411b7xQ/?spm_id_from=333.999.0.0&vd_source=5f3dfaeb7b92a24516d74b5e0327cf80
斯坦福 2022 年 AI 指数报告https://aiindex.stanford.edu/report/
涌现 https://mp.weixin.qq.com/s/cFQBqjKEnqnT6NMUMRZN9A
https://book.douban.com/subject/1543713/
‘Sparks of AGI’ – Bombshell GPT-4 Pape https://www.youtube.com/watch?v=Mqg3aTGNxZ0&ab_channel=AIExplained
微软CTO对话比尔·盖茨:GPT-4与人工智能的未来https://mp.weixin.qq.com/s/_9COZ-YjQ5rnlTd3_BR9sA